Playlist
Show Playlist
Hide Playlist
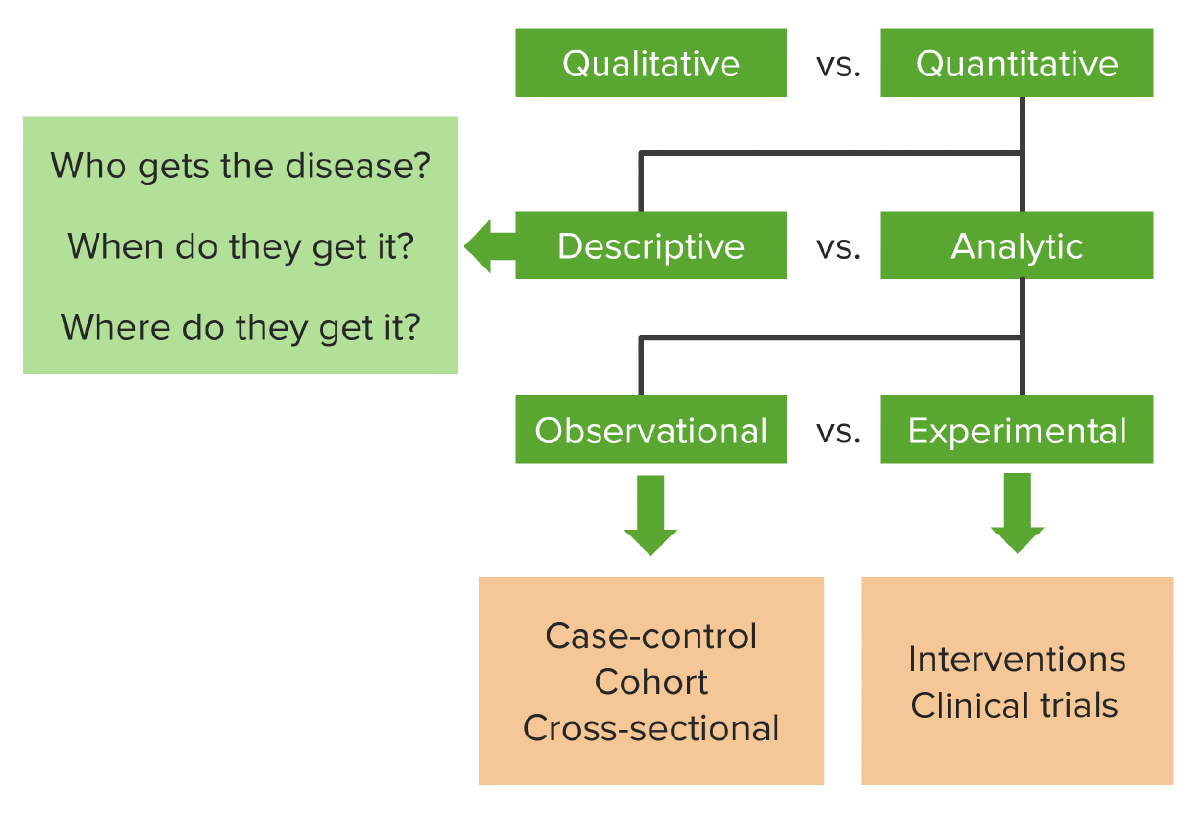
Cross-sectional Study – Observational Studies (Study Designs)

-
Slides 07 ObservationalStudies Epidemiology.pdf
-
Reference List Epidemiology and Biostatistics.pdf
-
Download Lecture Overview
00:00 Now let's talk about how we would approach this question in a cross-sectional scenario. Cross-section refers to a moment in time, a cross-section in a long tube of time. So we don't know what's happening before, after, just what's happening right now. Tt's good for measuring prevalence in the sense that how many people have a disease or a condition right now, that's what prevalence really is, the proportion of the population that has a certain outcome that we care about. So let's say we have a sample of people, we're going to determine from the sample, how many smoke and how many don't smoke and we're going to determine from these two groups, smokers and non-smokers, how many have lung cancer and how many don't have lung cancer, that's it. 00:45 The exposure is smoking, the outcome is lung cancer and I'll compute the differences and I'll get perhaps an association between those who smoke and those who have lung cancer. 00:57 This is most commonly done in surveys, a lot of public health information comes out of these kinds of surveys, the media likes to report on cross-sectional surveys a lot as well because they're cheap and they're easy to understand. The problem is cross-sectional approaches cannot determine causality, because we can't tell what came first, the smoking or the lung cancer. It's entirely possible that I found some lung cancer patients who took up smoking after they got sick. It's unlikely, but it's possible. So cross-sectional approaches are not good for determining what came before and what came after, we ascertain exposure and outcome simultaneously.
About the Lecture
The lecture Cross-sectional Study – Observational Studies (Study Designs) by Raywat Deonandan, PhD is from the course Types of Studies.
Included Quiz Questions
Which of the following is best measured using a cross-sectional study?
- The number of cases of a disease at the present time
- The number of cases of new disease onset this year
- The number of people with a particular exposure and a rare disease
- The proportion of people who have a disease, given a particular exposure
- The number of deaths caused by a particular disease this year
What is a major disadvantage of cross-sectional studies?
- They can’t determine temporal associations.
- They are very expensive.
- They are inherently biased.
- They are time-intensive.
- They have low power.
Author of lecture Cross-sectional Study – Observational Studies (Study Designs)

Raywat Deonandan, PhD
Customer reviews
5,0 of 5 stars
| 5 Stars |
|
5 |
| 4 Stars |
|
0 |
| 3 Stars |
|
0 |
| 2 Stars |
|
0 |
| 1 Star |
|
0 |
